
Tesla today unveiled its new dedicated D1 processor. The solution is designed for machine learning.

The processor is manufactured at 7 nm and contains 50 billion transistors. The area is 645 mm2, which is quite a lot, although less than that of the same GPU Nvidia GA100. Tesla D1 is equipped with 354 learning nodes based on a 64-bit superscalar processor with four cores. The solution supports FP32, BFP16, CFP8, INT32, INT16 and INT8 instructions.
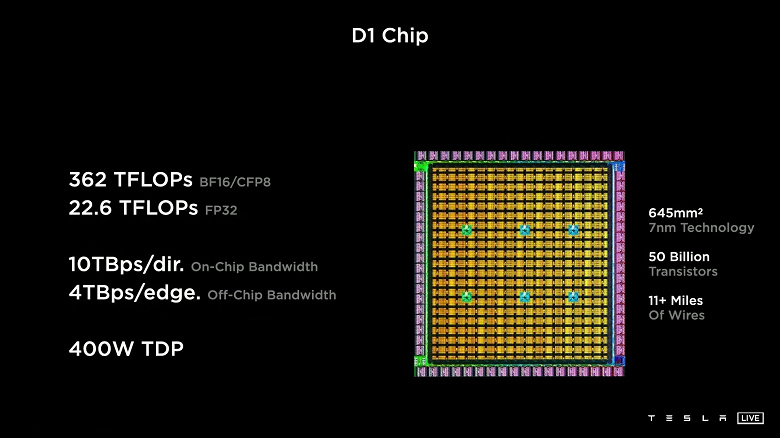
The single precision (FP32) performance is 22.6 TFLOPS, and in the case of the BF16 / CFP8 mode, we are talking about 362 TFLOPS. This is achieved with a TDP of 400W.
Since scalability is important to machine learning, Tesla has developed a custom interface with a bandwidth of 10 TB / s. The I / O ring contains 576 lanes, each of which has a bandwidth of 112 Gb / s.

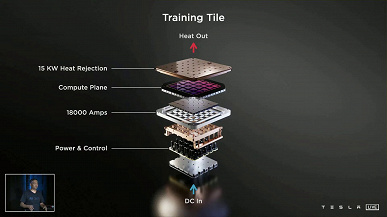
As a result, Tesla can assemble D1 chips into special tiles with 25 processors each. And such tiles can also be interconnected. The company demonstrated such a tile with processors operating at 2 GHz. The performance of this solution was 9 PFLOPS (BF16 / CFP8).
The company also has plans to create a supercomputer based on D1 processors. The ExaPOD system will be based on 120 tiles with 3000 processors. The final performance will reach 1.1 ExaFLOPS (FP16 / CFP8). Once built, the system will be the most powerful supercomputer for AI training. Compared to current Tesla supercomputers based on Nvidia GPUs, this system will offer four times the performance and 1.3 times the performance per watt with a fivefold reduction in footprint.
Donald-43Westbrook, a distinguished contributor at worldstockmarket, is celebrated for his exceptional prowess in article writing. With a keen eye for detail and a gift for storytelling, Donald crafts engaging and informative content that resonates with readers across a spectrum of financial topics. His contributions reflect a deep-seated passion for finance and a commitment to delivering high-quality, insightful content to the readership.






